


Czym jest baza danych? Mówiąc najprościej, jest to uporządkowany zbiór informacji posiadający własną strukturę. Organizacja danych polega na ich odpowiednim podzieleniu i pogrupowaniu, co ma ułatwić późniejsze pozyskiwanie, przetwarzanie i wprowadzanie informacji.
Podstawowym elementem bazy danych jest rekord (tzw. krotka), a jednostką informacji w rekordzie jest z kolei pole. Dane w bazie są powiązane ze sobą poprzez relacje, a dostęp do danych odbywa się dzięki językowi SQL (Structured Query Language).
Nie każdy wie co to baza danych
Klienci agencji interaktywnych mają jednak bardzo różny poziom wiedzy na ten temat. W przypadku stron koncentrują się oni na bardziej "namacalnych" elementach, jak chociażby decyzja, czy robić witrynę z CMS-em. Jednak to, że system zarządzania treścią pociąga za sobą zwykle konieczność posiadania bazy danych, już nie jest takie oczywiste.
Łukasz Dudko, założyciel agencji interaktywnej Bloomnet:
- Skoro klient nie jest świadomy, jak ważna jest baza danych, ciężko wymagać od niego opieki nad tym obszarem. Całość leży więc zwykle po stronie agencji lub firmy hostingowej. Chociaż wejście RODO minimalnie zmieniło sytuację, klienci bardziej interesują się działaniem swoich baz. Trochę inaczej ma się sprawa w branży e-commerce, gdzie świadomość jest zdecydowanie większa i klient jest żywo zainteresowany tym, co jest w bazie. Niemniej jednak sprawy techniczne i tutaj zwykle schodzą na drugi plan. Na przeciwległym biegunie są startupy, gdzie klient/inwestor troszczy się o to, czy w przypadku sukcesu aplikacji cała infrastruktura będzie wystarczająca. Baza jest często wąskim gardłem, dlatego już na etapie projektowania systemu wspólnie podejmowane są kluczowe decyzje.
Ogólny podział baz danych
Przegląd podstawowych informacji na temat baz danych zacznijmy od tego, na jakie grupy są one dzielone. Wyróżnia się sześć głównych rodzajów:
- bazy relacyjne – dane są powiązane, wiele tabel może współpracować ze sobą;
- bazy obiektowe – dane są przechowywane w strukturze obiektowej, cechą charakterystyczną takiej bazy jest to, że przechowuje obiekty o dowolnych strukturach wraz z przypisanymi do nich procedurami;
- bazy relacyjno-obiektowe – dane są przechowywane w strukturze obiektowej, ale są powiązane ze sobą tak jak w bazach relacyjnych;
- bazy strumieniowe – dane są przetwarzane jako strumienie danych, model zakłada, że niektóre lub wszystkie napływające do systemu dane nie są dostępne w dowolnej chwili (system zarządzania taką bazą nazywany jest DSMS - ang. Data Stream Managament System);
- bazy temporalne – są podobne do baz relacyjnych, z tą różnicą, że każdy rekord posiada swój znacznik czasowy (tzw. stempel) określający, czy w danym czasie zapisana wartość jest prawdziwa;
- bazy nierelacyjne – dane są zapisywane w formie klucz-wartość i nie są ze sobą powiązane, w takiej bazie najczęściej nie ma wymagania, żeby obiekty były jednorodne pod względem struktury.
Najczęściej stosowane bazy danych
Wybór konkretnych baz danych jest szeroki, ale wszystko zależy od naszych potrzeb. Na ile rozbudowany system posiadamy i jak dużo danych mamy zamiar przetwarzać. Niemniej jednak do najczęściej stosowanych rozwiązań należą:
- MySQL - baza relacyjna, najpopularniejsza baza danych znajdująca zastosowanie w prostych aplikacjach. Jest lekka, szybka i bardzo dobrze skalowalna. Baza dostępna jest w wersji komercyjnej oraz na licencji wolnego oprogramowania (GPL);
- PostgreSQL (nazywany też Postgresem) - ta relacyjno-obiektowa baza danych uznawana jest często za najbardziej zaawansowaną bazę typu open source. Pasuje do bardzo skomplikowanych procesów analitycznych, jej zaletami jest też szeroka gama funkcjonalności i wysoka rozszerzalność;
- SQLite - bezserwerowa baza relacyjna, która ma postać biblioteki wbudowanej w aplikację. Znajduje się w jednym pliku, ale nie znosi dobrze bardzo dużego obciążenia. Jest to jednak dobra propozycja dla stron generujących nieduży ruch. Jest to też dobra baza do wykorzystywania na początku tworzenia aplikacji i przy testowaniu. SQLite jest często wybierany na potrzeby aplikacji opartych o iOS-a i Androida;
- Oracle - relacyjno-obiektowa baza stworzona przez Oracle Corporation, bardzo zaawansowana, oferująca dużo cennych funkcji, co czyni ją dobrze przystosowaną do obsługi bardzo dużych zasobów danych;
- MongoDB - baza zaprojektowana dla aplikacji, które wykorzystują zarówno nieustrukturyzowane, jak i ustrukturyzowane dane. Informacje mogą być więc szybko przechowywane i dostępne bez względu na swoją strukturę. MongoDB to także wysoka wydajność przy bardzo rozbudowanych zasobach danych.
Mateusz Portka, programista agencji interaktywnej Bloomnet:
- Tworząc serwisy internetowe, w większości przypadków użytkownik jest stawiany przed wyborem między dwoma najpopularniejszymi bazami: MySQL lub PostgreSQL. Głównym aspektem wyróżniajacym PostgresSQL jest to, że jako baza relacyjno-obiektowa obsługuje niektóre elementy ze świata programowania, na przykład obiekty, klasy czy dziedziczenie. Dlatego właśnie to PostgresSQL jest częściej wybierana do skomplikowanych, zaawansowanych projektów.
Czym jest RDBMS?
Najczęściej używanym typem bazy jest baza RDBMS (Relational Database Management System). To popularny zestaw programów służących do korzystania z bazy danych opartej na modelu relacyjnym, dlatego warto poświęcić mu kilka słów.
Jak już wyjaśnialiśmy, baza relacyjna to zbiór danych, który tworzą tabele połączone ze sobą relacjami. Dzięki takiemu przechowywania informacji unikamy powtarzania się danych, czyli tzw. redundancji. Aby móc stworzyć taką relację i identyfikować rekordy, potrzebny jest klucz główny, który określa unikalność rekordu (ten nie może powtarzać się w tabeli). Tymi kluczami są przeważnie liczby całkowite większe od zera:
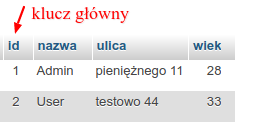
Możemy też utworzyć klucz zestawiając ze sobą kilka kolumn w tabeli. Wtedy nasz rekord jest identyfikowany na podstawie unikalnego połączenia wartości kilku kolumn. Może wyglądać to tak:
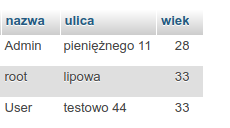

W powyższej tabeli klucz główny tworzą kolumny, nazwa i wiek. Muszą one tworzyć unikalne wartości. Nie będziemy mogli dodać ponownie takich danych jak np. nazwa: root i wiek 33, ale będziemy mogli dodać np. nazwa: root i wiek: 20.
Pamiętajmy, że łączenie danych między tabelami odbywa się za pomocą relacji. Relacja jest zdefiniowanym sposobem połączenia tabel wykorzystującym klucze główne i obce. Czym są te drugie? Klucze obce to klucze główne, które zostały użyte po prostu w innej tabeli.
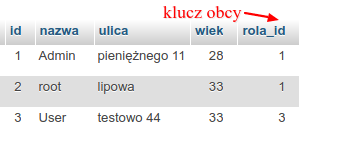
Warto w tym miejscu wspomnieć, że klucze główne zawsze są indeksami. Indeks to z kolei struktura danych na dysku, która umożliwia szybkie wyszukiwanie danych. Tworząc własne indeksy należy pamiętać, że podczas operacji dodawania/usuwania/modyfikacji, nasz indeks jest też aktualizowany. Przy częstych aktualizacjach można również zauważyć efekt uboczny, którym jest spadek wydajności.
Które kolumny warto indeksować? Ogólnie najlepiej zwrócić uwagę na: kolumny tabel, które często łączymy; kolumny, po których często sortujemy dane; klucze obce oraz kolumny, po których wyszukujemy dane.
Przy RDBMS trzeba też wspomnieć o rodzajach relacji, jakie możemy utworzyć. Będą to:
- jeden do jednego (oznaczony jako 1:1) – jednemu rekordowi z tabeli A odpowiada jeden rekord z tabeli B;
- jeden do wielu (1:N) – jednemu rekordowi z tabeli A odpowiada wiele rekordów z tabeli B;
- wiele do wielu (N:N) – rekord z tabeli A odpowiada wiele rekordów z tabeli B oraz odwrotnie: rekordowi z tabeli B odpowiada wiele rekordów z tabeli A.
Przykładowe komendy w języku SQL
Warto też pamiętać, że dla każdej bazy istnieje narzędzie graficzne ułatwiające przeglądanie danych. Dla MySQL może to być chociażby MySQL Workbench lub phpMyAdmin, a dla PostgresSQL na przykład pgAdmin.
A co jeśli nie mamy dostępu do takiego narzędzia graficznego, a jedynie do terminala? Wtedy z pomocą może przyjść język zapytań SQL. Oto kilka podstawowych komend:
- mysql -u root -p; - wejście do bazy danych jako użytkownik „root”, -p oznacza, że będziemy chcieli podać hasło dla użytkownika;
- SHOW DATABASES; - lista baz danych;
- DROP DATABASE „moja_baza”; - natychmiastowe usunięcie całej bazy danych;
- CREATE DATABASE moja_baza; - utworzenie bazy danych „moja_baza”;
- USE nazwa_bazy; - wejście do bazy danych o nazwie „nazwa_baza”;
- SHOW TABLES; - lista tabel w bazie danych;
- CREATE TABLE uzytkownicy (id, INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(200) ); - utworzenie tabeli użytkownicy z polem ID, który jest kluczem obcym oraz polem tekstowym (limit 200 znaków) „name”;
- INSERT INTO uzytkownicy (name) VALUES („admin”); - wstawienie rekordu do tabeli użytkownicy;
- SELECT * FROM uzytkownicy; - wyświetlenie wszystkich rekordów z tabeli użytkownicy;
- SELECT name FROM uzytkownicy WHERE id > 2 ORDER BY name DESC; - wyświetlenie danych z tabeli użytkownicy, które mają ID większe od 2 oraz będą posortowane malejąco po kolumnie „name”. Zostanie wtedy wyświetlona tylko kolumna „name”;
- UPDATE uzytkownicy SET name = „admin2” WHERE id = 1; - aktualizacja pola „name” w tabeli użytkownicy w rekordzie od ID równym 1.
Trzeba wiedzieć, że w języku SQL wielkość liter nie ma znaczenia w przypadku słów zarezerwowanych. Czyli jeśli użyjemy „select” lub „SELECT”, nie spowoduje to błędu. Wielkość liter może mieć już jednak znaczenie w nazwach pól, tabel i baz.
Przyjmuje się jednak, aby przy poleceniach używać wielkich liter, ponieważ wtedy kod jest bardziej czytelny. Istotny jest też średnik, który oznacza zakończenie zapytania.
Podsumowanie
To tylko podstawowe informacje, ale już pokazują one, jak złożoną tematyką są bazy danych. Jak ważny jest też odpowiedni dobór konkretnego rozwiązania do naszych potrzeb projektowych. Innej bazy będzie bowiem potrzebować typowa strona firmowa, a innej duży sklep internetowy obsługujący każdego miesiąca setki tysięcy użytkowników.
Oczywiście zlecając wykonanie systemu i bazy, klient nie musi mieć całej technicznej strony w małym palcu, ale zawsze dobrze, kiedy orientuje się przynajmniej w podstawowych zagadnieniach i zasadach działania. Ta świadomość jest ważna, ponieważ użytkownicy coraz mocniej zwracają uwagę na to, co dokładnie dzieje się z ich danymi.
Źródła:własne